
TLDR: Learning to read a word involves learning one piece of a large network of interconnected information about the language. When teaching reading vocabulary, you need to pick words in pockets of the network where there are gaps for that student, and where the word will provide the strongest connections to other words in their neighborhood of the network.
…
Most people think of knowledge about words as being like storing files in a drawer. When you need a word you look up the file, and it has a range of information associated with it (the stuff in the file). Thus, the goal of learning words is to pack as many files into the drawer as possible.
This is the wrong way to think about it.
The file drawer idea misses a crucial detail about word knowledge: words exist in neighborhoods of language structure. Effective learning (and teaching) means focusing on neighborhoods that offer the most knowledge for the learner at that time.
What really happens during vocabulary learning is that we grow our network of language knowledge (network in this sense is only a metaphor, but a very useful one). This knowledge is made up of all the structure of the words we encounter, including what they look + sound like, the things they point to in our environment (i.e., their meaning), and how they co-occur with other words in different methods of communication (like books, conversation, and so on). Growing this knowledge isn’t filling files in a file drawer; rather, (to use a different metaphor) it is more like building up your social network to stay connected with all the people and groups you care about in your day-to-day activities in the world.
You can think about clusters of words as being related in neighborhoods of language structure, and the neighborhoods can exist for all sorts of different types of structure. As a result, one word can belong to more than one neighborhood, and a neighborhood will consist of many different words. The neighborhoods are defined by all the different aspects of language structure that are important for comprehension and use. For example, words are related based on the speech sounds they contain, how they look (the letters they contain), their meaning, the types of prefixes and suffixes they have, whether or not they appear in the same spoken language or printed language context, and so on.
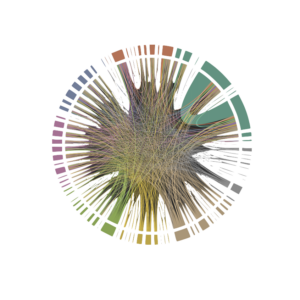
Below is a visual of what this type of structure looks like using some of the language neighborhoods in our technology. Bars of color on the outer rim represent specific neighborhoods of the language, and connections between them show visually how many words are shared across the different neighborhoods. Wide bars represent big neighborhoods and lots of words shared across them, and narrower bars represent smaller ones. For example, the light green neighborhood in the lower left portion of the circle is the neighborhood of words containing the letter “A”. This neighborhood has connections to many others, and when you learn words with that structure, other structure (from connected neighborhoods) comes along with it.
Take the word BERRY. This word has neighbors based on how it looks (BELLY, BETTY, BARRY), how it sounds (VERY, HAIRY, WARY), and how it looks and sounds (like MERRY, FERRY). It is also in a dense neighborhood of the network in terms of its meaning (there are lots of different types of berries, and other fruit like them). Of course, print, speech, and meaning aren’t all independent of each other; to take one example, morphological structure (prefixes, suffixes, etc.) is a type of structure in the language where the three come together.
We learn about all these different aspects of the language at the same time – even though we aren’t aware of all the learning that goes on in our mind. So picking dense pockets of knowledge is important during learning because of all of the interconnected structure. In education, we often only think about the obvious pockets of structure, like words that share the spelling and sound structure of _ERRY, or “types of fruit”. This is for good reason: we like to be able to explain the structure to students, and provide instruction around it.
But in reality there are more subtle aspects of the language that our learning picks up on – not just the structure that is obvious on the surface. These deeper structural elements of the language are what makes our technology useful: it detects similarity across all aspects of the language at once, and detects where the gaps are and what neighborhoods to focus on.
So, when teaching students to read words we should be sensitive to the neighborhoods of structure occupied by many other similar words. Most often, if a student is having trouble reading a word, it is because they need support with the neighborhood of words that look and sound like them. But we should also be giving students experiences with neighborhoods of meaning where they are lacking knowledge.
Identifying the deep, overlapping structures of the student’s knowledge network is hard, and isn’t well captured by traditional measures of assessing word knowledge. This part of the process (identifying the neighborhoods of structure and where the student needs to fill their knowledge network) is where technology should come in. This is what cognitive (machine learning) models do: they learn the structure in the same way as a student would, and then can tell us which neighborhood is most effective for learning (see our post about digital twins for more on this topic).
Utilizing neighborhood structure when making decisions about what to teach makes learning faster and more efficient. The goal of learning is to populate a student’s knowledge with dense neighborhoods of words based on the many different types of information they contain and how they co-occur in the language environment. To do this, you need technology that knows what the student needs at any given moment, and can take advantage of all this information in the knowledge network at the same time.